ojAlgo has a new web site, and it's essentially a blog. All content from this blog has been moved/copied there, and future posts will only appear at the ojAlgo web site.
http://www.ojalgo.org
Tuesday, 19 March 2019
Monday, 18 February 2019
Oracle's JVMs HotSpot, Graal CE & Graal EE
Benchmarking the HotSpot, Graal CE and Graal EE doing matrix multiplication
The HotSpot JVM will eventually be replaced by Graal which is about to be released at v1.0. Graal comes in 2 flavours – a free community edition (CE) and a commercial enterprise edition (EE). The EE has some performance optimisations that the CE doesn't. In particular it has auto-vectorization.
This is a follow-up to the earlier post Quick test to compare HotSpot and OpenJ9. This time the main objective is to compare the Graal CE and Graal EE. The general message on the performance of Graal CE seems to be that it is roughly on par with HotSpot – better at some things and worse at others, but about the the same on average. Presumably Graal EE will perform better than HotSpot.
Let's test those JVMs using code that will definitely benefit from auto-vectorization, matrix multiplication, and to test that using 3 commonly used pure Java linear algebra libraries:
The test performs matrix-matrix multiplication on square dense matrices of various sizes: 100, 150, 200, 350, 500, 750 and 1000. The libraries have made different choices on how to store the elements and how to implement multiplication. In particular ojAlgo is multithreaded, and the others are not. The goal here is not to determine which library is the fastest, but rather to get an idea about what happens when you change the JVM.
The chart below shows the speed (throughput, ops/min) for the various library/JVM combinations for each of the different matrix sizes.

How much will Oracle charge for the EE version?
In the previous post Quick test to compare HotSpot and OpenJ9 you can see how Graal CE compares to OpenJ9.
The benchmark code is here: https://github.com/optimatika/ojAlgo-linear-algebra-benchmark
The raw results (*.log and *.csv files) can be found here: https://github.com/optimatika/ojAlgo-linear-algebra-benchmark/tree/develop/results/2019/02/oracles-jvms-hotspot-graal-ce-graal-ee
The HotSpot JVM will eventually be replaced by Graal which is about to be released at v1.0. Graal comes in 2 flavours – a free community edition (CE) and a commercial enterprise edition (EE). The EE has some performance optimisations that the CE doesn't. In particular it has auto-vectorization.
This is a follow-up to the earlier post Quick test to compare HotSpot and OpenJ9. This time the main objective is to compare the Graal CE and Graal EE. The general message on the performance of Graal CE seems to be that it is roughly on par with HotSpot – better at some things and worse at others, but about the the same on average. Presumably Graal EE will perform better than HotSpot.
- JDK 1.8.0_161, Java HotSpot(TM) 64-Bit Server VM, 25.161-b12
- JDK 1.8.0_192, GraalVM 1.0.0-rc12, 25.192-b12-jvmci-0.54 GraalVM CE
- JDK 1.8.0_192, GraalVM 1.0.0-rc12, 25.192-b12-jvmci-0.54 GraalVM EE
Let's test those JVMs using code that will definitely benefit from auto-vectorization, matrix multiplication, and to test that using 3 commonly used pure Java linear algebra libraries:
- Apache Commons Math (ACM) v3.6.1
- Efficient Java Matrix Library (EJML) v0.37.1
- ojAlgo v47.0.1-SNAPSHOT
The test performs matrix-matrix multiplication on square dense matrices of various sizes: 100, 150, 200, 350, 500, 750 and 1000. The libraries have made different choices on how to store the elements and how to implement multiplication. In particular ojAlgo is multithreaded, and the others are not. The goal here is not to determine which library is the fastest, but rather to get an idea about what happens when you change the JVM.
The chart below shows the speed (throughput, ops/min) for the various library/JVM combinations for each of the different matrix sizes.

Interpretation
The chart speaks for itself and the results are as expected. Graal CE is typically slower than HotSpot, and Graal EE faster. The difference between the CE and EE versions of Graal is significant.How much will Oracle charge for the EE version?
In the previous post Quick test to compare HotSpot and OpenJ9 you can see how Graal CE compares to OpenJ9.
Test details
This test was executed on a Google Cloud Platform Compute Engine: n1-highmem-4 (4 vCPUs Intel Skylake Xeon, 26 GB memory).The benchmark code is here: https://github.com/optimatika/ojAlgo-linear-algebra-benchmark
The raw results (*.log and *.csv files) can be found here: https://github.com/optimatika/ojAlgo-linear-algebra-benchmark/tree/develop/results/2019/02/oracles-jvms-hotspot-graal-ce-graal-ee
Thursday, 7 February 2019
Quick test to compare HotSpot and OpenJ9
Benchmarking the HotSpot and OpenJ9 JVM:s doing matrix multiplication
AdoptOpenJDK comes in two flavours – one with the usual HotSpot JVM and one with OpenJ9.
Unfortunately I could only find builds based on OpenJDK 8, but the Graal JVM is the latest possible built just a couple of days ago.
Which is faster? Most likely the answer to that depends on what you're testing. I decided to test matrix multiplication, and to test that using 3 commonly used pure Java linear algebra libraries.
The chart below shows the speed (throughput, ops/min) for the various library/JVM combinations for each of the different matrix sizes.

Graal: Graal was consistently slower than HotSpot (half speed). This is the community edition (CE) of Graal. I've learned that (full) support for vectorization will only be in the enterprise edition (EE). I'm guessing that the EE will give performance similar to that of HotSpot.
The speed differences shown here are significant! Regardless of library and matrix size, performance could be halved or doubled by choosing another JVM. Looking at combinations of libraries and JVM:s there is an order of magnitude in throughput to be gained by choosing the right combination.
This will not translate to an entire system/application being this much slower or faster – matrix multiplication is most likely not the only thing it does. But, perhaps you should test how whatever you're working on performs with a different JVM.
The benchmark code is here: https://github.com/optimatika/ojAlgo-linear-algebra-benchmark
The raw results (*.log and *.csv files) can be found here: https://github.com/optimatika/ojAlgo-linear-algebra-benchmark/tree/develop/results/2019/02/quick-test-to-compare-hotspot-and-openj9
- JDK 11.0.2, OpenJDK 64-Bit Server VM, 11.0.2+9
- JDK 11.0.2, Eclipse OpenJ9 VM, openj9-0.12.1
After completing the first round of executions I decided to also add Graal.
- JDK 1.8.0_192, GraalVM 1.0.0-rc12, 25.192-b12-jvmci-0.54
Which is faster? Most likely the answer to that depends on what you're testing. I decided to test matrix multiplication, and to test that using 3 commonly used pure Java linear algebra libraries.
- Apache Commons Math (ACM) v3.6.1
- Efficient Java Matrix Library (EJML) v0.37.1
- ojAlgo v47.0.1-SNAPSHOT
The chart below shows the speed (throughput, ops/min) for the various library/JVM combinations for each of the different matrix sizes.
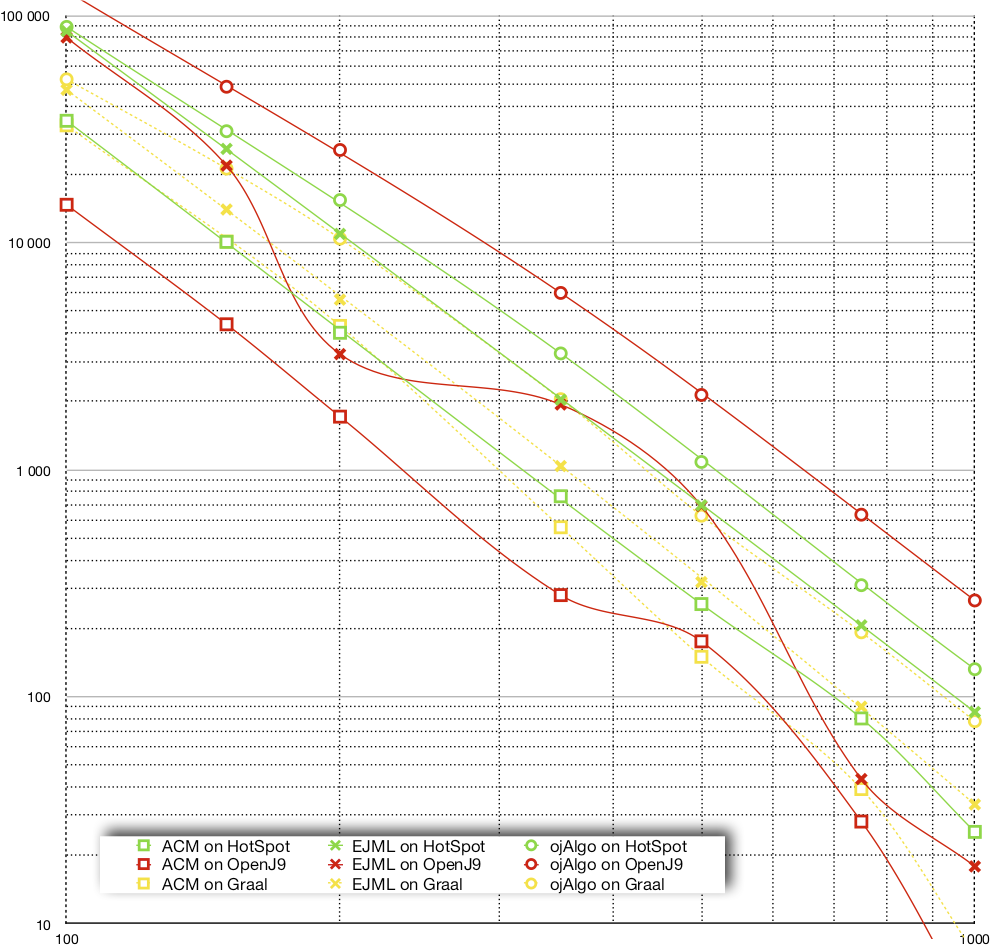
Interpretation
OpenJ9: Switching from HotSpot to OpenJ9 makes ojAlgo faster, ACM slower and EJML fluctuates between roughly the same performance and much slower. It seems OpenJ9 is less stable in its results than HotSpot. Apart from the fluctuations with EJML it widens the gap between the slowest and the fastest code. OpenJ9 makes the fast even faster and the slow even slower.Graal: Graal was consistently slower than HotSpot (half speed). This is the community edition (CE) of Graal. I've learned that (full) support for vectorization will only be in the enterprise edition (EE). I'm guessing that the EE will give performance similar to that of HotSpot.
The speed differences shown here are significant! Regardless of library and matrix size, performance could be halved or doubled by choosing another JVM. Looking at combinations of libraries and JVM:s there is an order of magnitude in throughput to be gained by choosing the right combination.
This will not translate to an entire system/application being this much slower or faster – matrix multiplication is most likely not the only thing it does. But, perhaps you should test how whatever you're working on performs with a different JVM.
Test details
This test was executed on a Google Cloud Platform Compute Engine: n1-highmem-4 (4 vCPUs Intel Skylake Xeon, 26 GB memory).The benchmark code is here: https://github.com/optimatika/ojAlgo-linear-algebra-benchmark
The raw results (*.log and *.csv files) can be found here: https://github.com/optimatika/ojAlgo-linear-algebra-benchmark/tree/develop/results/2019/02/quick-test-to-compare-hotspot-and-openj9
Subscribe to:
Posts (Atom)