Most developers are aware of the possibility to use either a JVM from Oracle or "just" OpenJDK, but few consider using any of the other alternatives. There are more alternatives!
https://en.wikipedia.org/wiki/List_of_Java_virtual_machines
What if choosing one of the alternatives could significantly improve the performance of your application?
I frequently see discussions and benchmarks comparing different libraries (that solve the same problem). Comparing Java performance to that of native code is also common, but I don't think I've ever seen a benchmark comapring different JVM:s. I decided to do this - I decided to run the Java Matrix Benchmark using both the Oracle JVM and Zing from Azul Systems.
I haven't done it yet, but as part of the preparations, I've executed some smaller tests. Below you'll find the results from benchmarking matrix multiplication using 3 different pure Java linear algebra libraries on both the Oracle JVM and Azul's Zing.
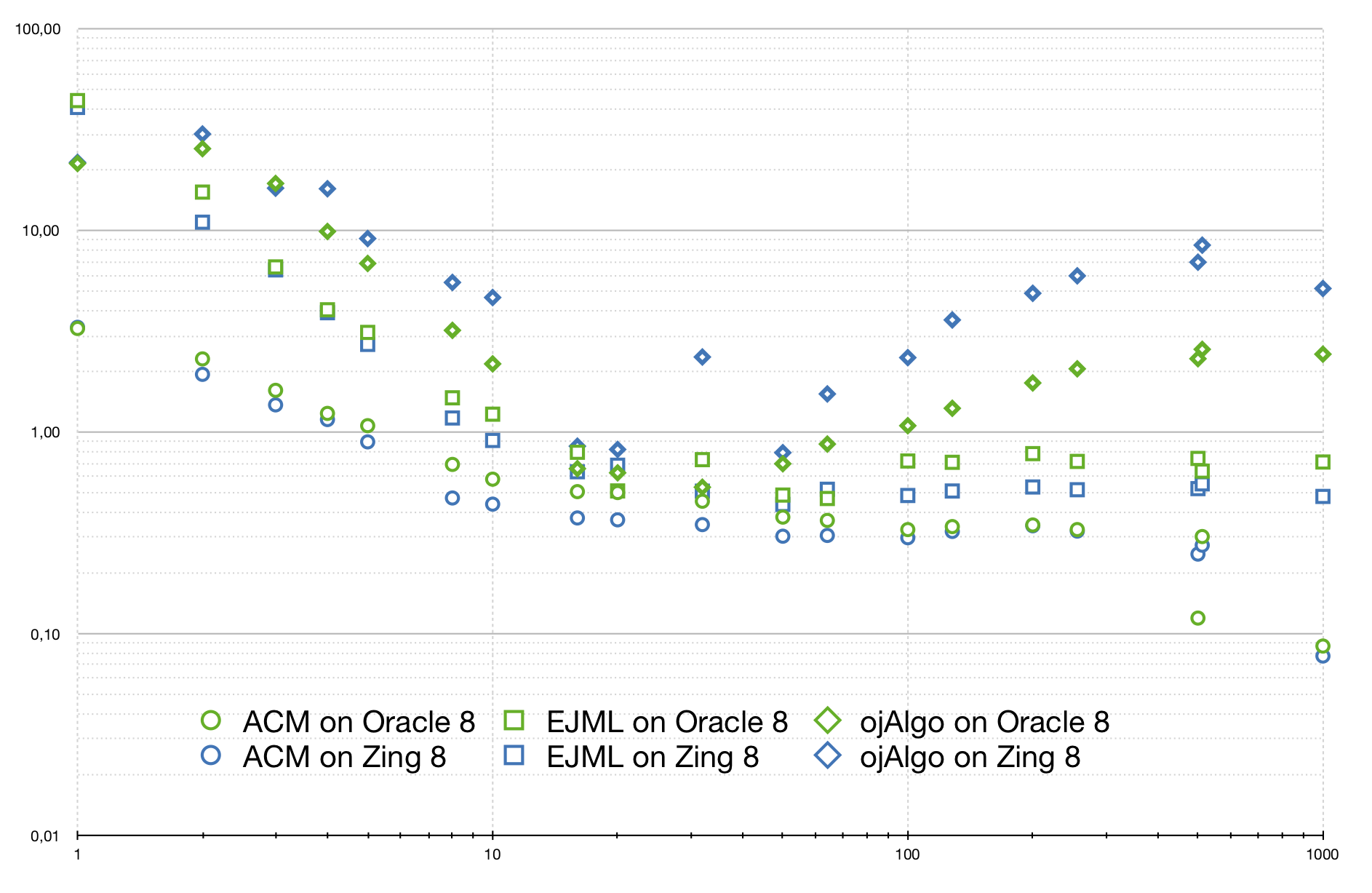
This chart shows the relative performance on matrix multiplication of 3 different Java linear algebra libraries, using 2 different JVM:s. The x-axis shows the (square) matrix size, and the y-axis the relative performance.
Which 3 Java linear algebra libraries?
- ojAlgo v45.0.0-SNAPSHOT
- EJML v0.33
- Apache Commons Math (ACM) v3.6.1
ojAlgo is the only multi-threaded library among these.
Which 2 JVM:s?
- JDK 1.8.0_161, VM 25.161-b12 (Oracle 8)
- JDK 1.8.0-zing_17.12.1.0, VM 1.8.0-zing_17.12.1.0-b1-product-azlinuxM-X86_64 (Zing 8)
Relative to what?
Actually a 4:th linear algebra library was benchmarked – Matrix Toolkits Java (MTJ) v1.0.7. It is based on netlib-java which use native code libraries if available. The machine in question had some plain/default version of ATLAS installed which was used. (just did 'sudo yum install atlas'). Since the actual matrix multiplication is done in native code the performance was essentially identical between the different JVM:s. This was used as a reference.
"1.0" on the y-axis represents the speed of MTJ/netlib-java/ATLAS. Then for the other library and JVM combinations you can see how much faster or slower they where.
Interpreting the results
These are my conclusions:
- The choice of JVM does make a difference (it did in this case) and Oracle is not necessarily the best option.
- Performance differences between the JVM:s are of the same magnitude as between different code libraries.
- Depending on which code library you use, the effects of changing JVM:s vary – you need to look at the individual combinations.
- ojAlgo is the only multi-threaded library here. This allows it to be more than 4 times faster than the other libraries (with the larger matrices). In those cases there is also a significant difference between Oracle and Zing – it's another 4x speed improvement. This would be vectorisation happening in the JVM. Modern JVM:s have support to automagically utilise SIMD instructions. This feature is brittle, it doesn't always happen! It seems Zing agreed with ojAlgo and managed to vectorise the code, where Oracle did not.
- Java is fast enough to sometimes be faster than native. In this case the native code library is not the fastest possible. I believe ATLAS, that was used in this case, can be tuned to perform better than it did here, and there are other alternatives (perhaps to purchase an Intel MKL license). But, unless you do something to ensure the best possible native performance, a good Java library may be faster (as shown here).
Look at that chart again. For the larger matrix sizes there is almost a 100x speed increase between the slowest and the fastest library/JVM combination.
What kind of machine was this run on?
The benchmark was executed on a Google Cloud Platform n1-standard-8 (8 vCPUs, 30 GB memory) with Intel Skylake processors.
Full execution output logs